之前写了一个简化版的使用 Python 查找目录中的重复文件,现在升级了一下,我们来提供一个友好的网页界面。
思路
上一个版本我们非常简单粗暴地将所有文件的 hash 扫描后保存到一个字典中,字典结构大概是这样的:
files = [{'hash1':['file/path...','file/path...']},
{'hash2':['file/path...','file/path...','file/path...']},
{'hash3':['file/path...']}]
然后通过一个循环找出 hash 值对应的数组长度大于 1 的数组,现在我们把这个扫描结果保存到数据库中,之后只要查询数据库即可找到重复的文件。
步骤
我们大致需要几个步骤就可以让程序跑起来:
git clone https://github.com/tobyqin/photodup.git # 克隆代码
cd photodup
pip install -r requirements.txt # 安装必要的依赖包
python db.py # 创建DB表结构
表结构不需要太复杂:
| id | hash | name | path | Existed |
|---|---|---|---|---|
| 1 | ab3d | DCS_001.JPG | path/to/DSC_001.JPG | 1 |
| 2 | 1d2c | DCS_002.JPG | path/to/DSC_002.JPG | 2 |
然后开始扫描你要检查的目录。
1
python scan.py dir1 dir2
你可以传入一个或者多个目录,默认只检索 jpg 文件,也可以修改config.py里的配置项来自定义。扫描结束后,启动 web 服务即可。
1
python web.py
顺利的话用浏览器打开 http://127.0.0.1:5001 就可以看到一个友好的网页,可以通过文件 hash 或者文件名来清理重复文件,可以预览图片文件。
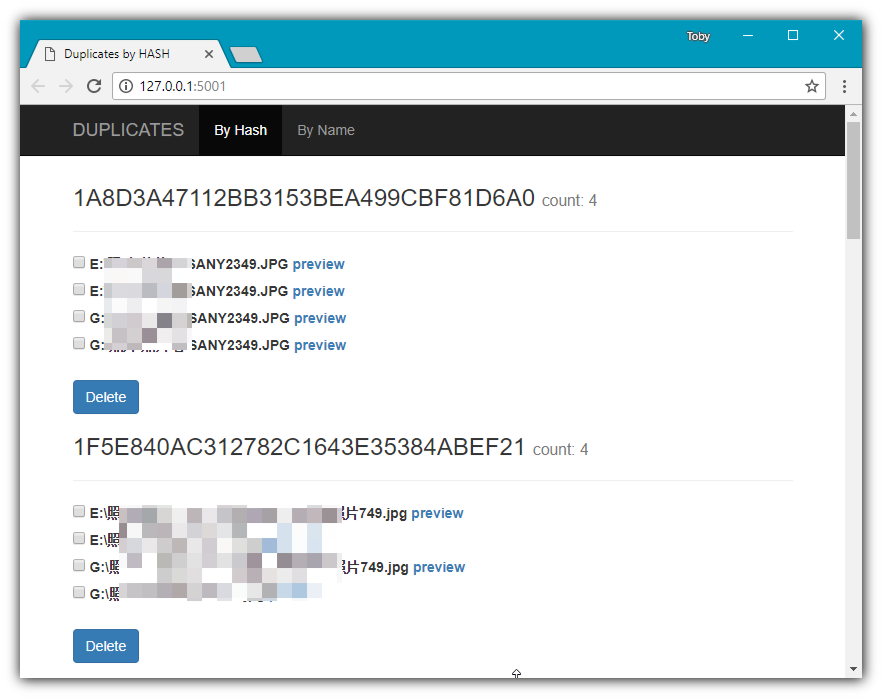
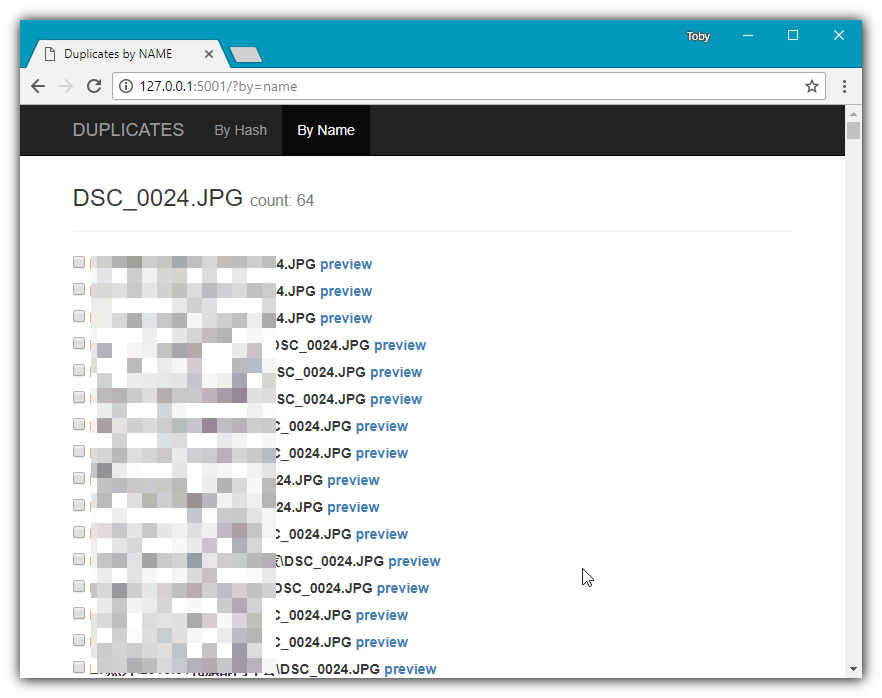
原理&总结
升级后的重复文件清理工具总共也不过两三百行代码,但是已经算是一个比较完整的程序,使用起来也方便了很多。升级过程中用到了前后端数据库各方面的知识,不管你的想法多简单,真正动手去实现才会有收获。
项目地址:https://github.com/tobyqin/photodup
技术栈:Python, SQL, Flask, Bootstrap, Jquery, CSS.